تأملات في استراتيجيات تحديد أولويات المنتج
تم النشر:
تأملات في استراتيجيات تحديد أولويات المنتج
من دورة في إدارة المنتجات المعتمدة على الذكاء الاصطناعي  رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.

تم النشر:
من دورة في إدارة المنتجات المعتمدة على الذكاء الاصطناعي رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
تم النشر:
خواطر على هامش دورة لإدارة منتجات الذكاء الاصطناعي 
تم النشر:
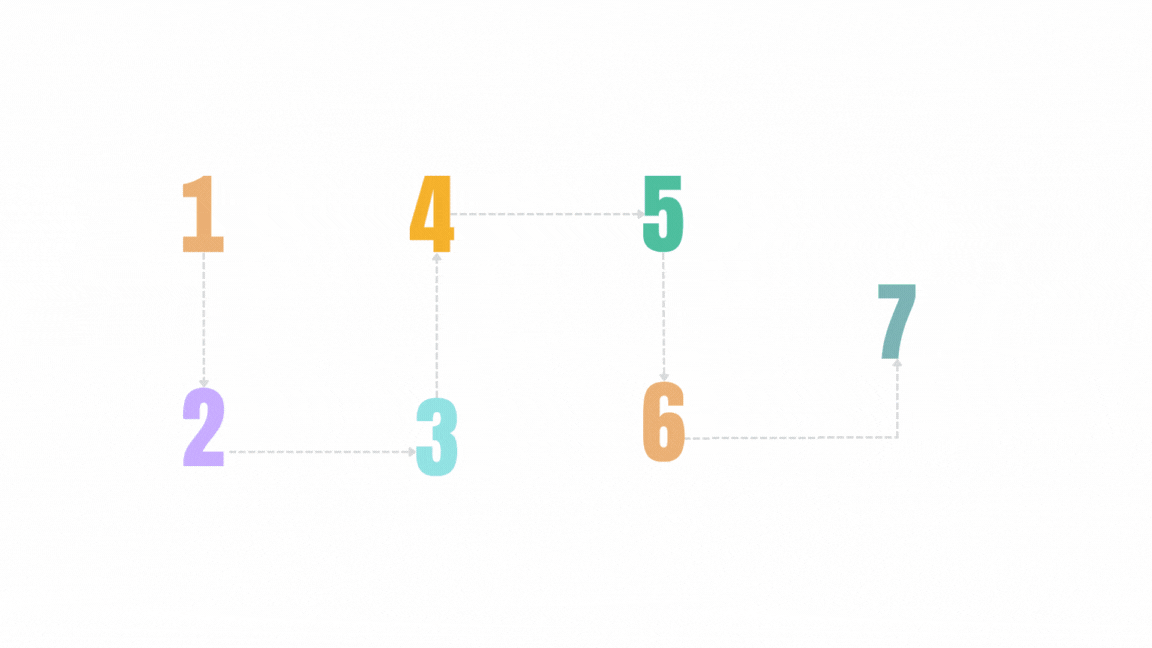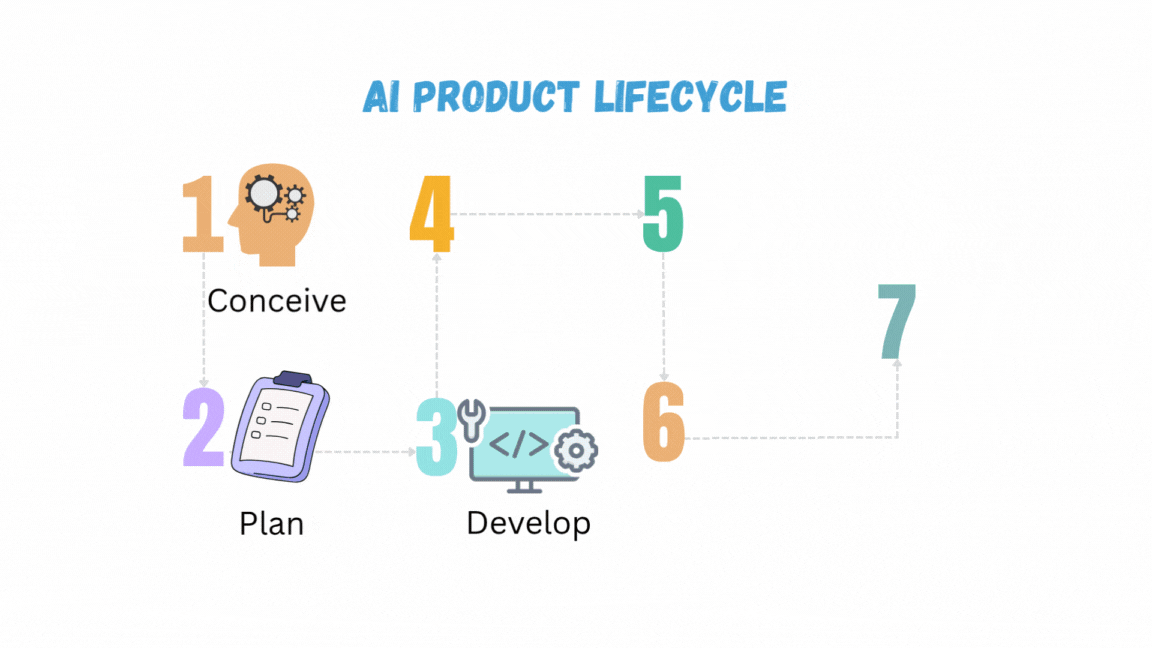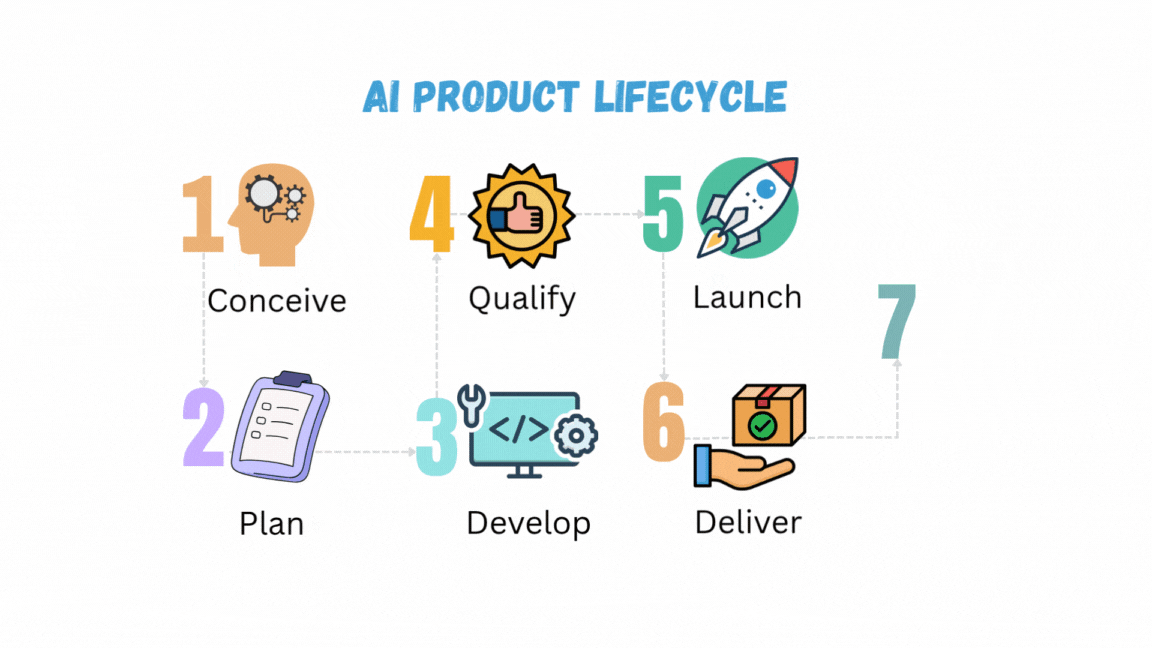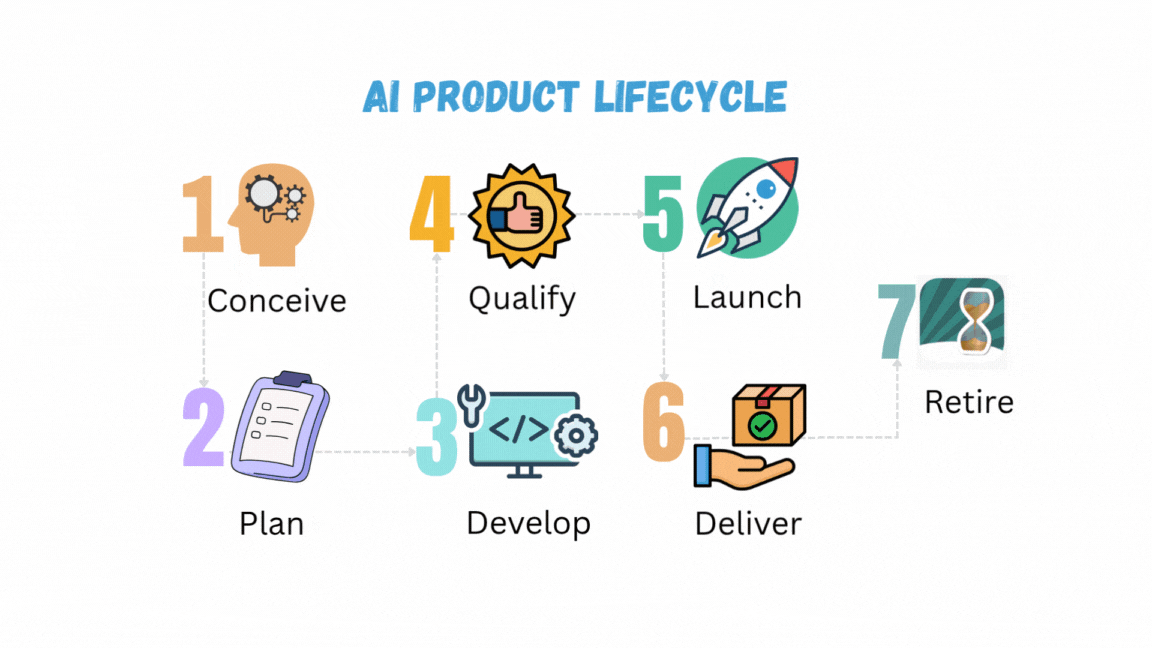
تم النشر:
ملء النماذج يمكن أن يكون مملًا ويستغرق وقتًا طويلًا. هذا غالبًا ما يؤدي إلى إحباط المستخدمين وتقديمات غير مكتملة. ولكن، الذكاء الاصطناعي التفاعلي، مثل نموذج اللغة Gemini 1.5 Pro، يغير كيفية تفاعلنا مع النماذج.
تم النشر:
ملء النماذج يمكن أن يكون مملًا ويستغرق وقتًا طويلًا. هذا غالبًا ما يؤدي إلى إحباط المستخدمين وتقديمات غير مكتملة. ولكن، الذكاء الاصطناعي التفاعلي، مثل نموذج اللغة Gemini 1.5 Pro، يغير كيفية تفاعلنا مع النماذج.
تم النشر:
ملء النماذج يمكن أن يكون مملًا ويستغرق وقتًا طويلًا. هذا غالبًا ما يؤدي إلى إحباط المستخدمين وتقديمات غير مكتملة. ولكن، الذكاء الاصطناعي التفاعلي، مثل نموذج اللغة Gemini 1.5 Pro، يغير كيفية تفاعلنا مع النماذج.
تم النشر:
عالم علم البيانات يمكن أن يكون مرعبًا للمبتدئين، حيث يمتلئ بالمصطلحات المعقدة والمفاهيم المعقدة. ولكن ماذا لو كان لديك مساعد ذكاء اصطناعي بجانبك، جاهز لشرح هذه المفاهيم بعبارات بسيطة وإرشادك خلال عملية التعلم؟ هذا هو المكان الذي يأتي فيه قوة توليد المعلومات المدعوم بالاسترجاع (RAG).
تم النشر:
عالم علم البيانات يمكن أن يكون مرعبًا للمبتدئين، حيث يمتلئ بالمصطلحات المعقدة والمفاهيم المعقدة. ولكن ماذا لو كان لديك مساعد ذكاء اصطناعي بجانبك، جاهز لشرح هذه المفاهيم بعبارات بسيطة وإرشادك خلال عملية التعلم؟ هذا هو المكان الذي يأتي فيه قوة توليد المعلومات المدعوم بالاسترجاع (RAG).
تم النشر:
 استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، في هذا الجزء سنواصل استكشاف كيفية إعادة ضبط نموذج Gemma2-9b على مجموعة بيانات عربية باستخدام مكتبة Keras وKeras_nlp وتقنية LoRA. سنتناول كيفية إعداد البيئة، تحميل النموذج، إجراء التعديلات اللازمة، ثم تدريب النموذج باستخدام التوازي النموذجي لتوزيع معلمات النموذج عبر عدة وحدات تسريع.
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، في هذا الجزء سنواصل استكشاف كيفية إعادة ضبط نموذج Gemma2-9b على مجموعة بيانات عربية باستخدام مكتبة Keras وKeras_nlp وتقنية LoRA. سنتناول كيفية إعداد البيئة، تحميل النموذج، إجراء التعديلات اللازمة، ثم تدريب النموذج باستخدام التوازي النموذجي لتوزيع معلمات النموذج عبر عدة وحدات تسريع.
تم النشر:
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، سنواصل في الجزء الثاني استكشاف الأساليب المخصصة لإعادة ضبط نموذج Gemma-2b على مجموعة بيانات عربية لتحسين أدائه. سنستخدم مكتبة Transformers وتقنية qLoRA (التكيف منخفض الرتبة المكمم) لتقليل استهلاك الذاكرة.
تم النشر:
عند العمل على مشروع يتطلب التعامل مع اللغة العربية، قد تتساءل عما إذا كان يجب استخدام توليد النصوص المدعوم بالاسترجاع (RAG) أو تعديل نموذج موجود باستخدام مجموعة بيانات عربية جديدة. في هذه السلسلة من الدروس المكونة من جزئين، سنستكشف كلا الخيارين: استخدام RAG وتعديل نموذج باستخدام بيانات عربية، تحديداً ويكيبيديا. سنركز طوال المشروع على النماذج مفتوحة المصدر، باستخدام Gemma 2 Instruct ونموذج تضمين مفتوح المصدر. سنستفيد أيضًا من إطار العمل LangChain لتبسيط عملية بناء RAG وتعديل النموذج. دعونا نبدأ بالتطبيق العملي.
تم النشر:
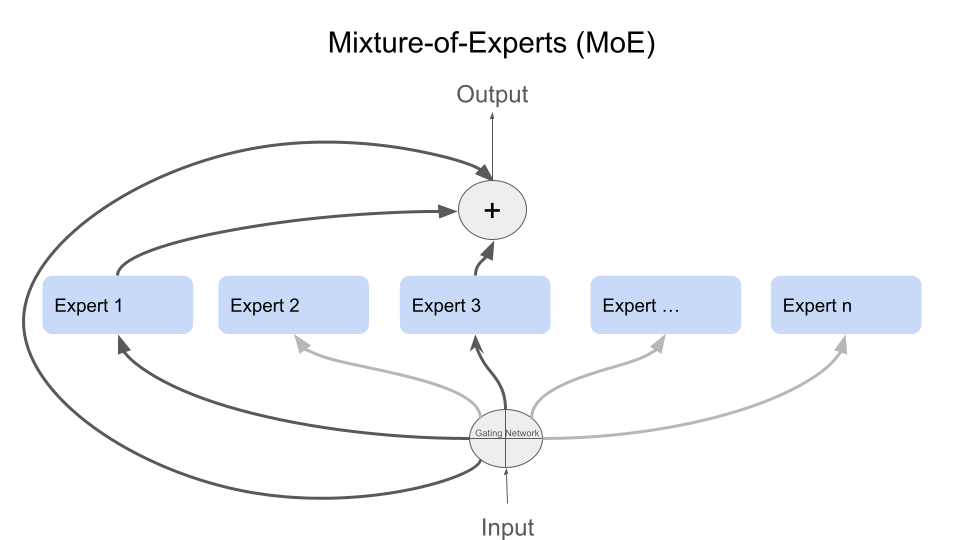
تم النشر:
 مصدر الصور [3]
مصدر الصور [3]
تم النشر:
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، في هذا الجزء سنواصل استكشاف كيفية إعادة ضبط نموذج Gemma2-9b على مجموعة بيانات عربية باستخدام مكتبة Keras وKeras_nlp وتقنية LoRA. سنتناول كيفية إعداد البيئة، تحميل النموذج، إجراء التعديلات اللازمة، ثم تدريب النموذج باستخدام التوازي النموذجي لتوزيع معلمات النموذج عبر عدة وحدات تسريع.
تم النشر:
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، سنواصل في الجزء الثاني استكشاف الأساليب المخصصة لإعادة ضبط نموذج Gemma-2b على مجموعة بيانات عربية لتحسين أدائه. سنستخدم مكتبة Transformers وتقنية qLoRA (التكيف منخفض الرتبة المكمم) لتقليل استهلاك الذاكرة.
تم النشر:
عند العمل على مشروع يتطلب التعامل مع اللغة العربية، قد تتساءل عما إذا كان يجب استخدام توليد النصوص المدعوم بالاسترجاع (RAG) أو تعديل نموذج موجود باستخدام مجموعة بيانات عربية جديدة. في هذه السلسلة من الدروس المكونة من جزئين، سنستكشف كلا الخيارين: استخدام RAG وتعديل نموذج باستخدام بيانات عربية، تحديداً ويكيبيديا. سنركز طوال المشروع على النماذج مفتوحة المصدر، باستخدام Gemma 2 Instruct ونموذج تضمين مفتوح المصدر. سنستفيد أيضًا من إطار العمل LangChain لتبسيط عملية بناء RAG وتعديل النموذج. دعونا نبدأ بالتطبيق العملي.
تم النشر:
ملء النماذج يمكن أن يكون مملًا ويستغرق وقتًا طويلًا. هذا غالبًا ما يؤدي إلى إحباط المستخدمين وتقديمات غير مكتملة. ولكن، الذكاء الاصطناعي التفاعلي، مثل نموذج اللغة Gemini 1.5 Pro، يغير كيفية تفاعلنا مع النماذج.
تم النشر:
عالم علم البيانات يمكن أن يكون مرعبًا للمبتدئين، حيث يمتلئ بالمصطلحات المعقدة والمفاهيم المعقدة. ولكن ماذا لو كان لديك مساعد ذكاء اصطناعي بجانبك، جاهز لشرح هذه المفاهيم بعبارات بسيطة وإرشادك خلال عملية التعلم؟ هذا هو المكان الذي يأتي فيه قوة توليد المعلومات المدعوم بالاسترجاع (RAG).
تم النشر:
من دورة في إدارة المنتجات المعتمدة على الذكاء الاصطناعي رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
تم النشر:
تم النشر:
مصدر الصور [3]
تم النشر:
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، في هذا الجزء سنواصل استكشاف كيفية إعادة ضبط نموذج Gemma2-9b على مجموعة بيانات عربية باستخدام مكتبة Keras وKeras_nlp وتقنية LoRA. سنتناول كيفية إعداد البيئة، تحميل النموذج، إجراء التعديلات اللازمة، ثم تدريب النموذج باستخدام التوازي النموذجي لتوزيع معلمات النموذج عبر عدة وحدات تسريع.
تم النشر:
استكمالًا لسلسلة الدروس التعليمية التي تركز على اللغة العربية في التعامل مع النماذج اللغوية الضخمة، سنواصل في الجزء الثاني استكشاف الأساليب المخصصة لإعادة ضبط نموذج Gemma-2b على مجموعة بيانات عربية لتحسين أدائه. سنستخدم مكتبة Transformers وتقنية qLoRA (التكيف منخفض الرتبة المكمم) لتقليل استهلاك الذاكرة.
تم النشر:
عند العمل على مشروع يتطلب التعامل مع اللغة العربية، قد تتساءل عما إذا كان يجب استخدام توليد النصوص المدعوم بالاسترجاع (RAG) أو تعديل نموذج موجود باستخدام مجموعة بيانات عربية جديدة. في هذه السلسلة من الدروس المكونة من جزئين، سنستكشف كلا الخيارين: استخدام RAG وتعديل نموذج باستخدام بيانات عربية، تحديداً ويكيبيديا. سنركز طوال المشروع على النماذج مفتوحة المصدر، باستخدام Gemma 2 Instruct ونموذج تضمين مفتوح المصدر. سنستفيد أيضًا من إطار العمل LangChain لتبسيط عملية بناء RAG وتعديل النموذج. دعونا نبدأ بالتطبيق العملي.
تم النشر:
ملء النماذج يمكن أن يكون مملًا ويستغرق وقتًا طويلًا. هذا غالبًا ما يؤدي إلى إحباط المستخدمين وتقديمات غير مكتملة. ولكن، الذكاء الاصطناعي التفاعلي، مثل نموذج اللغة Gemini 1.5 Pro، يغير كيفية تفاعلنا مع النماذج.
تم النشر:
عالم علم البيانات يمكن أن يكون مرعبًا للمبتدئين، حيث يمتلئ بالمصطلحات المعقدة والمفاهيم المعقدة. ولكن ماذا لو كان لديك مساعد ذكاء اصطناعي بجانبك، جاهز لشرح هذه المفاهيم بعبارات بسيطة وإرشادك خلال عملية التعلم؟ هذا هو المكان الذي يأتي فيه قوة توليد المعلومات المدعوم بالاسترجاع (RAG).
تم النشر:
تم النشر:
تم النشر:
تم النشر:
مصدر الصور [3]
تم النشر:
من دورة في إدارة المنتجات المعتمدة على الذكاء الاصطناعي رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
تم النشر:
خواطر على هامش دورة لإدارة منتجات الذكاء الاصطناعي
تم النشر:
تم النشر:
من دورة في إدارة المنتجات المعتمدة على الذكاء الاصطناعي رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
تم النشر:
عالم علم البيانات يمكن أن يكون مرعبًا للمبتدئين، حيث يمتلئ بالمصطلحات المعقدة والمفاهيم المعقدة. ولكن ماذا لو كان لديك مساعد ذكاء اصطناعي بجانبك، جاهز لشرح هذه المفاهيم بعبارات بسيطة وإرشادك خلال عملية التعلم؟ هذا هو المكان الذي يأتي فيه قوة توليد المعلومات المدعوم بالاسترجاع (RAG).
تم النشر:
خواطر على هامش دورة لإدارة منتجات الذكاء الاصطناعي