
Mixture of Experts: دليلك الشامل لفهم تقنية الذكاء الاصطناعي الثورية
تم النشر:
Mixture of Experts: دليلك الشامل لفهم تقنية الذكاء الاصطناعي الثورية
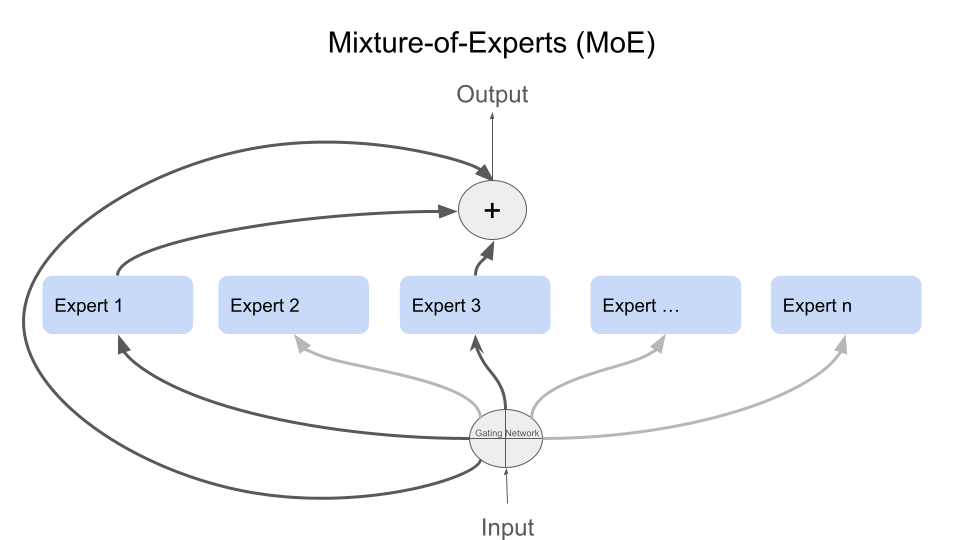
الشكل 1: تمثيل توضيحي لتقنية Mixture of Experts
عندما طُرح نموذج Mixtral 7x8b لأول مرة، استحوذت تقنية “خليط الخبراء” (MoE) على اهتمامي بشكل كبير. وعلى الرغم من أنني حاولت حينها استكشاف المفهوم، إلا أنني لم أتعمق بما يكفي لفهم إمكاناته الكاملة.
اليوم، أعود لاستكشاف MoE بحماس متجدد. أعتقد أن هذه التقنية واعدة وملهمة لتوليد أفكار مبتكرة ومنبثقة منها تسهل بناء نماذج ذكاء اصطناعي بكفاءة عالية.
المقدمة
تعتبر تقنية Mixture of Experts (MoE) إحدى التقنيات المتقدمة التي تهدف إلى تحسين أداء نماذج الذكاء الاصطناعي، مما يتيح لها معالجة المهام المعقدة بشكل أكثر فعالية. تستند MoE إلى مجموعة من “الخبراء” المتخصصين، حيث يُكلف كل خبير بمعالجة جزء معين من المهام بشكل مستقل. في هذا المقال، نستعرض كيفية عمل هذه التقنية، وفوائدها، والتحديات التي تواجهها، بالإضافة إلى أبرز تطبيقاتها العملية.
ما هي تقنية Mixture of Experts؟
تقنية Mixture of Experts هي إطار عمل في التعلم العميق يسمح بتقسيم المهام إلى أجزاء صغيرة توزع على مجموعة من الشبكات العصبية المتخصصة، حيث يُعرف كل منها بـ”الخبير”. يستفيد النموذج من خبرة كل خبير، مما يعزز الكفاءة والدقة في معالجة المهام المعقدة مقارنة بالنماذج التقليدية التي تعتمد على شبكة واحدة ضخمة.
لتبسيط الفكرة: تخيل فريق عمل، كل فرد فيه متخصص في مجال معين. عندما يواجه الفريق تحديًا صعبًا، يقوم كل خبير بدراسته من وجهة نظره الخاصة، ويقدم الحل الأمثل من منظوره. بعدها يأتي “مدير” ليجمع كل الحلول ويختار الأفضل منها بناءً على طبيعة التحدي.
هذا هو بالضبط مبدأ عمل “خليط الخبراء”! إنها تقنية ذكاء اصطناعي تستخدم مجموعة من “الخبراء” (شبكات عصبية صغيرة)، كلٌّ منها متخصص في جزء معين من البيانات أو المهام. عند إدخال بيانات جديدة، يتم توزيعها على الخبراء بناءً على خبراتهم، حيث يعالج كل خبير الجزء المخصص له. وفي النهاية، تقوم “بوابة” (شبكة عصبية خاصة) بدمج مخرجاتهم وتقدم الحل النهائي.
كيف تعمل تقنية MoE؟
تقنية MoE تعتمد على مبدأ توجيه المدخلات إلى الخبير الأنسب بناءً على طبيعته، وذلك عبر شبكة توجيه مركزية. يُعرف هذا النهج بـ “التوجيه الشرطي” حيث يختار النموذج مجموعة صغيرة من الخبراء لمعالجة المدخلات بناءً على مدى ملاءمتها. يؤدي هذا التوجيه إلى توفير الموارد الحاسوبية وتحقيق أعلى أداء للنموذج في مهام متنوعة مثل معالجة اللغات الطبيعية ورؤية الكمبيوتر.
المكونات الأساسية لـ MoE
1. شبكة التوجيه (Router Network)
شبكة التوجيه هي المسؤولة عن اختيار الخبراء الأكثر ملاءمة لكل مهمة، إذ تقوم بتحليل خصائص المدخلات باستخدام تقنيات مثل Softmax وتقرر توزيعها على الخبراء. تعتمد شبكة التوجيه على أوزان تتغير تدريجيًا خلال التدريب، مما يسمح لها بالتعلم الأمثل لعملية التوجيه.
2. الخبراء (Experts)
الخبراء هم شبكات عصبية متخصصة في معالجة نوع معين من المهام. يمكن أن يكون الخبير شبكة ذات بنية بسيطة مثل Feedforward Neural Network (FFN) أو بنية أكثر تعقيداً مثل الشبكات العميقة والمتقدمة. يتيح هذا التخصص للخبراء معالجة بيانات محددة بكفاءة أكبر، مما يحقق نتائج دقيقة بسرعة أعلى مقارنة بالنماذج التقليدية.
التفاصيل التقنية
آلية التوجيه
تستخدم آلية التوجيه معادلة Softmax لاختيار الخبراء الأنسب، حيث يتم حساب قيم التوجيه (Routing Weights) للمدخلات x عبر المعادلة:
Gσ(x) = Softmax(x⋅Wg)
حيث:
- x: المدخلات.
- Wg: مصفوفة الأوزان الخاصة بالتوجيه.
- Gσ: تمثل قيم التوجيه المحسوبة التي تحدد الخبراء الأنسب للتنفيذ.
حساب المخرجات
تتم معالجة المدخلات بواسطة مجموعة من الخبراء ويتم تجميع المخرجات وفقًا للوزن المحسوب لكل خبير. تتم هذه العملية عبر المعادلة التالية:
y = ∑ i=1 n G(x)i Ei(x)
حيث:
- G(x)i: وزن التوجيه للخبير i.
- Ei(x): المخرجات الناتجة عن الخبير i.
- n: عدد الخبراء المتاحين لمعالجة المدخلات.
المزايا والتحديات
المزايا
- كفاءة حوسبية عالية: تُفعّل MoE فقط مجموعة من الخبراء لكل عملية، مما يوفر في استهلاك الموارد.
- قابلية التوسع: توفر بنية MoE مرونة أكبر للتوسع مع الاحتفاظ بأداء متميز، حيث يمكن إضافة خبراء جدد بسهولة.
- تخصص أفضل في المهام: بفضل وجود خبراء متنوعين، يمكن للنموذج التخصص في مهام متنوعة بكفاءة.
- استخدام أمثل للموارد: يعمل عدد محدد من الخبراء في كل مرة، مما يقلل من متطلبات الحساب مقارنة بالنماذج الكاملة.
التحديات
- توازن الحمل بين الخبراء: قد يؤدي عدم التوزيع المتوازن إلى إرباك بعض الخبراء بينما يظل آخرون غير نشطين.
- تعقيد في التدريب: يتطلب تدريب نموذج MoE بنية معقدة وتنسيقًا دقيقًا.
- احتياجات ذاكرة عالية: تعتمد MoE على عدد كبير من الخبراء، مما يزيد من استهلاك الذاكرة.
- صعوبات في الضبط الدقيق: يتطلب ضبط شبكة التوجيه لتحقيق أفضل أداء دراسة دقيقة وتجربة مجموعة من المعاملات.
تطبيقات عملية لتقنية MoE
1. معالجة اللغات الطبيعية
- الترجمة الآلية: تخصص الخبراء في معالجة أنواع مختلفة من الجمل يمكن أن يزيد من دقة الترجمات.
- تحليل المشاعر: تخصيص الخبراء لفئات معينة من النصوص يمكن أن يسهم في تقديم نتائج أكثر دقة في التحليل.
- توليد النصوص: يتيح MoE إنتاج نصوص أكثر تماسكًا وسلاسة بفضل تخصيص الخبراء لمهام مختلفة.
2. معالجة الصور
- تصنيف الصور: يعزز تخصيص الخبراء لدراسة أنماط معينة دقة التصنيف.
- كشف الأجسام: يمكن تخصيص بعض الخبراء لاكتشاف أنواع معينة من الأجسام في الصور.
- تحليل المشاهد: تحسين أداء النماذج في التعرف على التفاصيل المختلفة للمشهد.
3. التطبيقات المالية
- تحليل المخاطر: يساعد تخصيص الخبراء على فحص مجموعة واسعة من البيانات المالية لتحليل المخاطر بدقة.
- التنبؤ بالأسعار: يمكن للخبراء تحليل اتجاهات السوق لتوقع حركة الأسعار بشكل أدق.
- كشف الاحتيال: تخصيص بعض الخبراء للتعرف على أنماط احتيالية معينة في المعاملات المالية.
أفضل الممارسات للتنفيذ
1. اختيار عدد الخبراء المناسب
- من الأفضل البدء بعدد صغير من الخبراء (مثلاً 2-8 خبراء) ومراقبة الأداء.
- زيادة عدد الخبراء بشكل تدريجي حسب الحاجة مع تجنب الإرباك في التوجيه.
- تقييم الكفاءة بشكل دوري للتأكد من الأداء الأمثل.
2. ضبط شبكة التوجيه
- استخدام Noisy Top-k Gating: لموازنة التوجيه وتقليل الحمل على الخبراء.
- تجربة معاملات ضوضاء مختلفة: تحسين توزيع الحمل على الخبراء وتخفيف عبء الحساب.
- مراقبة توزيع الحمل: يساعد على التأكد من أن جميع الخبراء يؤدون عملهم بشكل متوازن.
3. تحسين التدريب
- استخدام خسارة موازنة الحمل: لتحفيز شبكة التوجيه على توزيع العمل بالتساوي.
- تجربة أحجام دفعات مختلفة: لتحسين الأداء وزيادة الكفاءة.
- ضبط معدلات التعلم: بعناية للتأكد من استقرار التدريب وعدم التذبذب.
الاتجاهات المستقبلية لتقنية MoE
1. تحسين الكفاءة
- تطوير خوارزميات توجيه أفضل: لتحقيق توزيع أكثر دقة للمهام على الخبراء.
- تقليل استهلاك الذاكرة: لتلبية احتياجات النماذج الأكبر مع استخدام ذاكرة أقل.
- تحسين التوازي: لزيادة سرعة التدريب وتشغيل النماذج.
2. توسيع التطبيقات
- دمج MoE في المزيد من المجالات: كتحليل البيانات الطبية، الذكاء الصناعي للألعاب، وتطبيقات الذكاء الاصطناعي الصناعي.
- تطوير تطبيقات جديدة: بتخصيص الخبراء لتخصصات غير مسبوقة.
- تحسين الأداء في المهام المعقدة: لمهام تتطلب تميزًا في فهم السياق والمعاني الدقيقة.
الخاتمة
تقنية Mixture of Experts تُمثل نقطة تحول كبيرة في مجال الذكاء الاصطناعي، إذ تتيح تحقيق أداء عالٍ وتخصص أكثر كفاءة، خاصةً مع زيادة تعقيد المهام وتطورات الذكاء الاصطناعي. ومع استمرار الأبحاث والتطوير، يُتوقع أن تتوسع تطبيقات MoE أكثر وأن تسهم في تقديم حلول جديدة أكثر ذكاءً وفعالية في مجالات متنوعة.
المراجع والموارد الإضافية
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)
- يتناول هذا البحث فكرة دمج طبقات الـ MoE في الشبكات العصبية الكبيرة، ويستعرض كيفية تحقيق كفاءة في الأداء.
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Jun 2020)
- يناقش هذا البحث كيفية استخدام MoE لتوسيع نطاق النماذج الكبيرة عبر تقنيات حساب شرطية وشفافية تلقائية.
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (Dec 2021)
- يوضح كيف يمكن لـ MoE تحسين كفاءة نماذج اللغة من خلال توزيع الأعباء بين الخبراء.
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)
- يستعرض كيفية تطبيق MoE على نماذج الـ Transformers الضخمة، ويشرح تقنيات التوجيه لتقليل الاستهلاك الحوسبي.
- FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models (April 2022)
- يركز على تحسين نماذج MoE من خلال التدريب الديناميكي والنمذجة.
- Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models (May 2023)
- يدرس كيف يمكن لـ MoE أن يتكامل مع تقنيات الضبط الخاصة لتقديم أداء أفضل في نماذج اللغة.
 رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
رحلة فهم وتقييم ووعي أعمق بما يُحدث الفرق في عالم المنتجات.
 مصدر الصور [3]
مصدر الصور [3]