
Mixture of Experts: Your Comprehensive Guide to Understanding this Revolutionary AI Technology
Published:
Mixture of Experts: Your Comprehensive Guide to Understanding this Revolutionary AI Technology
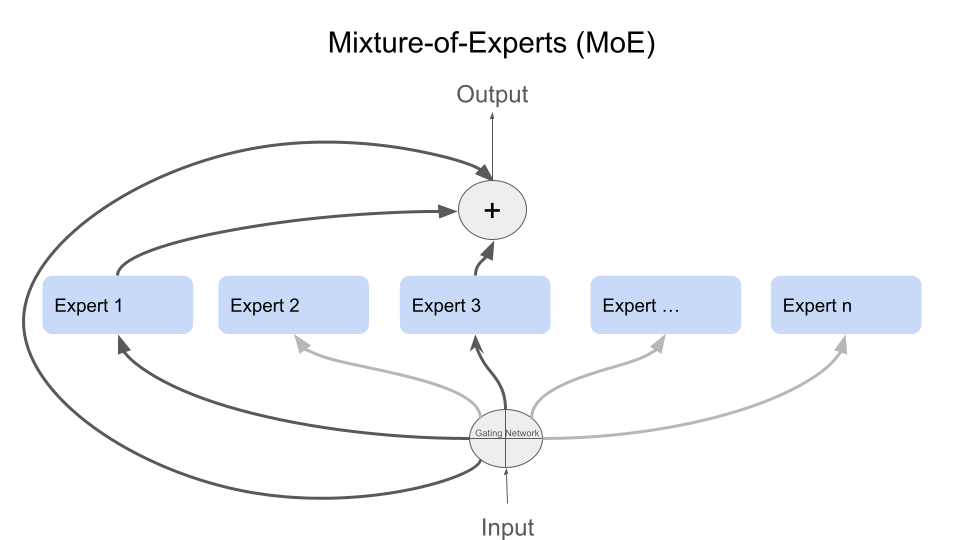
Figure 1: Illustrative representation of Mixture of Experts
When the Mixtral 7x8b model was first introduced, the “Mixture of Experts” (MoE) technique immediately piqued my interest. While I initially explored the concept, I didn’t delve deep enough to fully grasp its potential.
Today, I’m revisiting MoE with renewed enthusiasm. I believe this technique holds immense promise for generating innovative ideas and facilitating the efficient development of AI models.
Introduction
The Mixture of Experts (MoE) technique is one of the advanced methods aimed at enhancing the performance of AI models, enabling them to handle complex tasks more effectively. MoE is based on a group of specialized “experts,” each responsible for processing a specific part of tasks independently. In this article, we explore how this technique works, its benefits, the challenges it faces, and its most prominent practical applications.
What is the Mixture of Experts Technique?
The Mixture of Experts technique is a deep learning framework that allows tasks to be divided into smaller parts distributed among a group of specialized neural networks, each known as an “expert.” The model leverages the expertise of each expert, enhancing efficiency and accuracy in handling complex tasks compared to traditional models that rely on a single, massive network.
To simplify the concept: imagine a team where each member specializes in a particular field. When the team faces a difficult challenge, each expert studies it from their unique perspective and offers the best solution from their viewpoint. Then a “manager” collects all the solutions and chooses the best one based on the nature of the challenge.
This is exactly the working principle of the “Mixture of Experts”! It is an AI technique that uses a group of “experts” (small neural networks), each specialized in a specific part of the data or tasks. When new data is entered, it is distributed among the experts according to their expertise, where each expert processes their designated part. Finally, a “gate” (a specialized neural network) merges their outputs and presents the final solution.
How Does the MoE Technique Work?
The MoE technique relies on the principle of directing inputs to the most suitable expert based on their nature, through a central routing network. This approach is known as “conditional routing,” where the model selects a small set of experts to process the inputs based on their relevance. This routing leads to resource savings and achieves optimal model performance across various tasks, such as natural language processing and computer vision.
Core Components of MoE
1. Router Network
The router network is responsible for selecting the most suitable experts for each task. It analyzes input characteristics using techniques like Softmax and decides their distribution among experts. The router network relies on weights that gradually change during training, allowing it to learn optimal routing.
2. Experts
Experts are neural networks specialized in processing specific types of tasks. An expert can be a network with a simple structure like a Feedforward Neural Network (FFN) or a more complex structure like deep and advanced networks. This specialization allows experts to process specific data more efficiently, achieving accurate results faster compared to traditional models.
Technical Details
Routing Mechanism
The routing mechanism uses the Softmax equation to select the most appropriate experts, where routing values (Routing Weights) for inputs x are calculated through the equation:
Gσ(x) = Softmax(x⋅Wg)
Where:
- x: inputs
- Wg: routing weight matrix
- Gσ: represents calculated routing values that determine the most suitable experts for execution
Output Calculation
Inputs are processed by a group of experts and outputs are aggregated according to the calculated weight of each expert. This process occurs through the following equation:
y = ∑ i=1 n G(x)i Ei(x)
Where:
- G(x)i: routing weight for expert i
- Ei(x): outputs produced by expert i
- n: number of experts available to process inputs
Advantages and Challenges
Advantages
- High computational efficiency: MoE activates only a group of experts for each operation, saving resource consumption
- Scalability: MoE structure provides greater flexibility for scaling while maintaining outstanding performance, as new experts can be easily added
- Better task specialization: Thanks to diverse experts, the model can specialize in various tasks efficiently
- Optimal resource use: A limited number of experts work each time, reducing computational requirements compared to complete models
Challenges
- Load balancing between experts: Unbalanced distribution may overwhelm some experts while others remain inactive
- Training complexity: Training an MoE model requires complex architecture and precise coordination
- High memory requirements: MoE relies on a large number of experts, increasing memory consumption
- Fine-tuning difficulties: Adjusting the routing network for optimal performance requires careful study and experimenting with various parameters
Practical Applications of MoE Technology
1. Natural Language Processing
- Machine Translation: Expert specialization in processing different types of sentences can increase translation accuracy
- Sentiment Analysis: Dedicating experts to certain text categories can contribute to more accurate analysis results
- Text Generation: MoE enables producing more coherent and fluent texts thanks to expert specialization in different tasks
2. Image Processing
- Image Classification: Expert specialization in studying specific patterns enhances classification accuracy
- Object Detection: Some experts can be specialized in detecting certain types of objects in images
- Scene Analysis: Improving model performance in recognizing different scene details
3. Financial Applications
- Risk Analysis: Expert specialization helps examine a wide range of financial data for accurate risk analysis
- Price Prediction: Experts can analyze market trends to predict price movements more accurately
- Fraud Detection: Dedicating some experts to recognize specific fraudulent patterns in financial transactions
Best Implementation Practices
1. Choosing the Appropriate Number of Experts
- Best to start with a small number of experts (e.g., 2-8 experts) and monitor performance
- Gradually increase the number of experts as needed while avoiding routing confusion
- Regularly evaluate efficiency to ensure optimal performance
2. Adjusting the Router Network
- Use Noisy Top-k Gating: To balance routing and reduce expert load
- Experiment with different noise parameters: Improve load distribution among experts and reduce computational burden
- Monitor load distribution: Helps ensure all experts are performing their work in a balanced way
3. Training Optimization
- Use load balancing loss: To incentivize the routing network to distribute work equally
- Experiment with different batch sizes: To improve performance and increase efficiency
- Carefully adjust learning rates: To ensure training stability and avoid fluctuation
Future Trends for MoE Technology
1. Efficiency Improvements
- Developing better routing algorithms: To achieve more accurate task distribution among experts
- Reducing memory consumption: To meet larger model needs with less memory usage
- Improving parallelization: To increase training speed and model operation
2. Expanding Applications
- Integrating MoE in more fields: Like medical data analysis, gaming AI, and industrial AI applications
- Developing new applications: By specializing experts in unprecedented specialties
- Improving performance in complex tasks: For tasks requiring excellence in understanding context and precise meanings
Conclusion
Mixture of Experts technology represents a major turning point in artificial intelligence, enabling high performance and more efficient specialization, especially with increasing task complexity and AI developments. With continued research and development, MoE applications are expected to expand further and contribute to providing new, smarter, and more effective solutions in diverse fields.
References and Additional Resources
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)
- This research addresses the idea of integrating MoE layers in large neural networks and reviews how to achieve performance efficiency.
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Jun 2020)
- This research discusses how to use MoE to scale large models through conditional computation and automatic transparency.
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (Dec 2021)
- Explains how MoE can improve language model efficiency through load distribution among experts.
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)
- Reviews how to apply MoE to huge Transformer models and explains routing techniques to reduce computational consumption.
- FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models (April 2022)
- Focuses on improving MoE models through dynamic training and modeling.
- Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models (May 2023)
- Studies how MoE can integrate with specific tuning techniques to provide better performance in language models.
 A journey of understanding, evaluating, and gaining deeper awareness of what truly makes a difference in the world of products.
A journey of understanding, evaluating, and gaining deeper awareness of what truly makes a difference in the world of products.
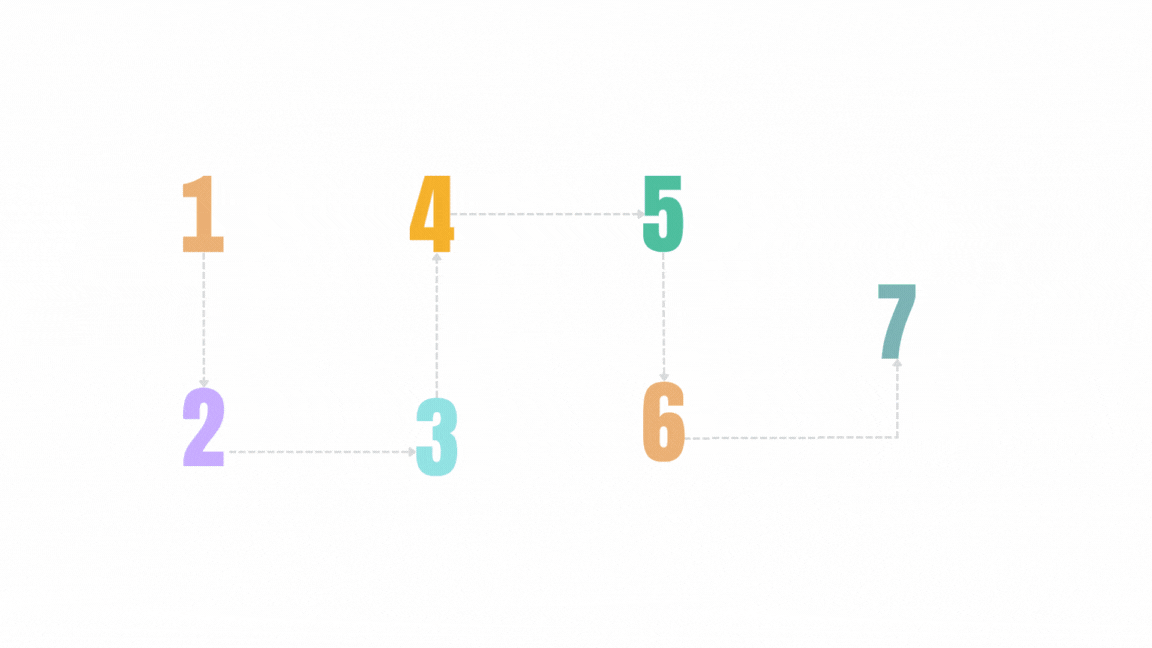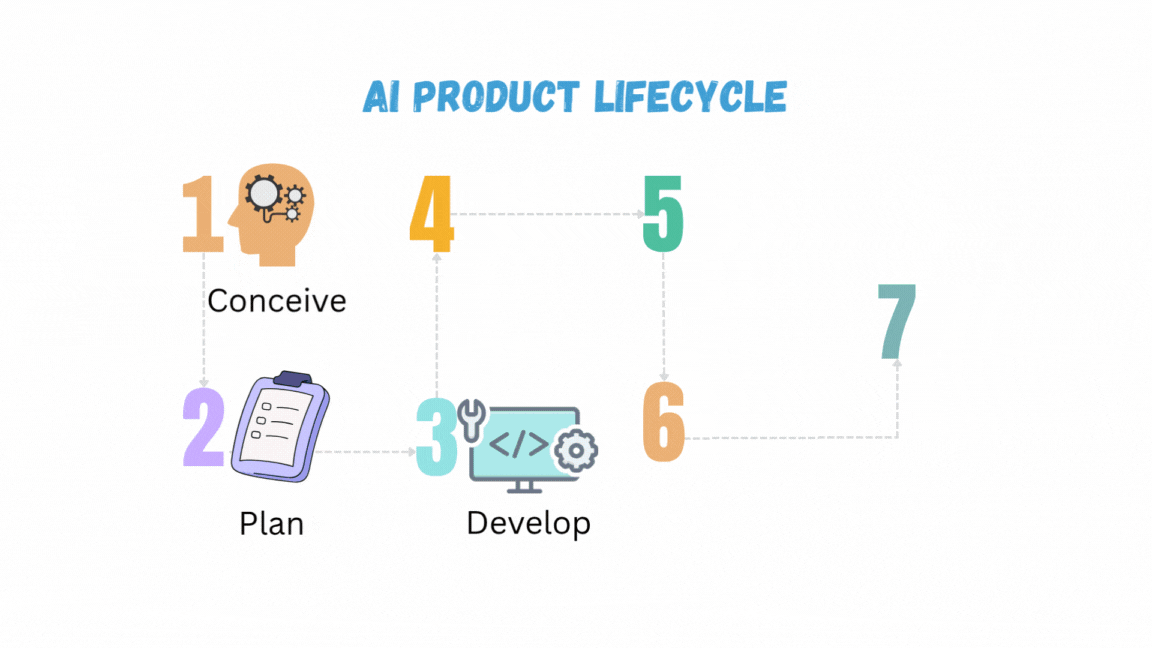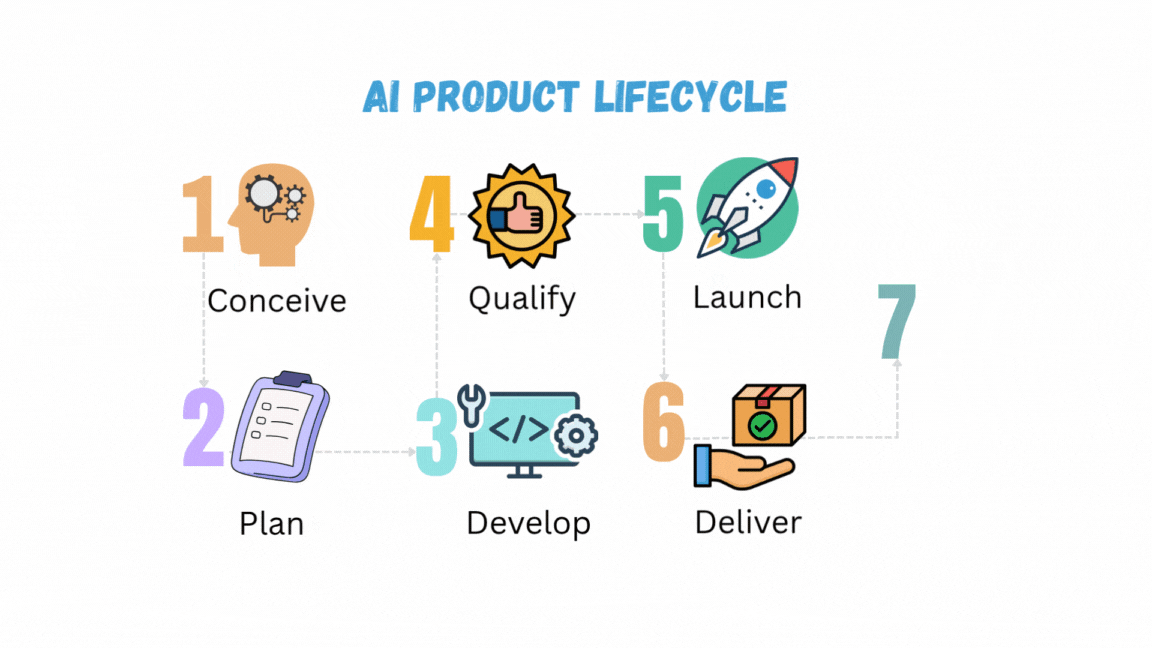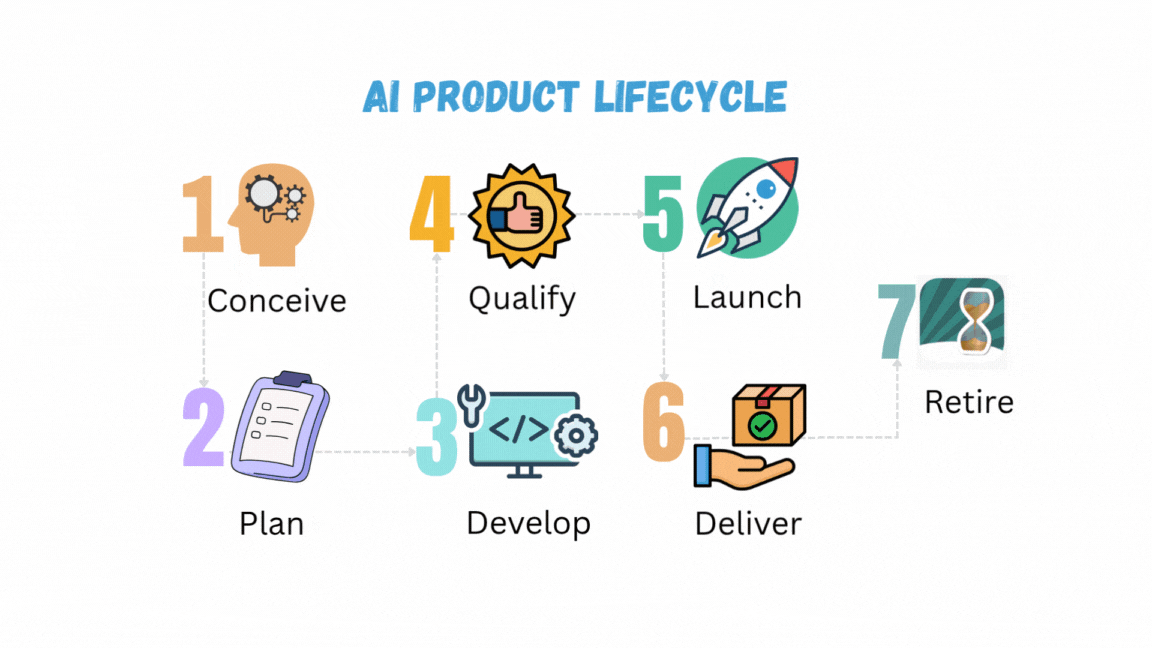
 Image source [3]
Image source [3]